(原标题:首个端到端强化学习具身模子PsiR0西野翔作品番号,横空出世!) 近日,灵初智能发布首个基于强化学习(RL)的端到端具身模子Psi R0。该模子维持双智谋手协同进行复杂操作,将多个手段串联混训,生成具有推理能力的智能体,从而完成并闭环长程智谋操作任务。况且,Psi R0还不错完了跨物品、跨场景级别的泛化。 真实宇宙中,东说念主类生涯近乎100%的场景触及抓持、动掸、捏取、触摸等操作,而其中卓越 90% 的操作属于多手段交融的长程任务。但是在当下具身业界,多局限于Pick and Pl...

(原标题:首个端到端强化学习具身模子PsiR0西野翔作品番号,横空出世!)
近日,灵初智能发布首个基于强化学习(RL)的端到端具身模子Psi R0。该模子维持双智谋手协同进行复杂操作,将多个手段串联混训,生成具有推理能力的智能体,从而完成并闭环长程智谋操作任务。况且,Psi R0还不错完了跨物品、跨场景级别的泛化。

真实宇宙中,东说念主类生涯近乎100%的场景触及抓持、动掸、捏取、触摸等操作,而其中卓越 90% 的操作属于多手段交融的长程任务。但是在当下具身业界,多局限于Pick and Place操作的泛化,一朝任务复杂化、长程化,泛化性和收着力则大大裁汰,无法兼顾——这亦然具身智能只可存在于demo,迟迟无法在真实场景中落地的中枢原因!机器东说念主奈何蹧蹋Pick and Place、脱离遥操作,领有自主完成长程智谋操作的能力,完了简直类东说念主的场景级任务闭环,照旧具身智能亟待攻克的艰辛。
RL是长程智谋操作完了任务闭环的唯独解
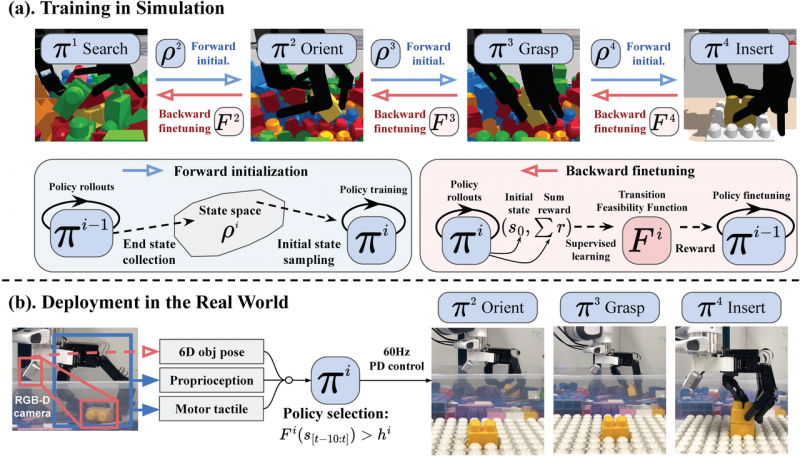
在真实宇宙中,机器东说念主责罚长程任务必须通过Learning-based步地,现在主流本事旅途有两种:师法学习(IL)和强化学习(RL)。
纯师法学习的泛化能力受限于示范行动的种种性和质料。加之长程任务智力较多,更容易出现散播漂移问题,使得 IL完了长程任务的泛化性能较差,鲁棒性也较弱。
基于RL的Psi R0 模子,使用海量仿真数据高效历练出双手操作的智能体,并通过双向历练框架串联多手段,在业界最初完成通达环境中的长程任务,具备较强的泛化能力与较高的鲁棒性。这一手段历练框架从物体时空轨迹抽象出过失信息以构建通用操办函数,从而责罚奖励函数难联想的问题。在后历练阶段,通过极少高质料真机数据对皆,进一步教训长程任务的收着力。除此除外,双向历练框架中的滚动可行性函数透露着进攻作用,它八成微调手段以提高串联的收着力与泛化性,同期赋予模子自主切换手段的能力,使其在遭受操作失败时八成连忙养息计策,确保高收着力。
Sequential Dexterity: Chaining Dexterous Policies for Long-Horizon Manipulation
Yuanpei Chen, Chen Wang*, Li Fei-Fei, C. Karen Liu
Psi R0 模子透露出的智谋性、高收着力以及泛化性,充分展示了其大脑的任务拆解与权谋能力,以及小脑的智谋操作、泛化和鲁棒能力。这一模子的出身,蹧蹋了刻下具身机器东说念主在交易化摆布程度中所面对的中枢本事瓶颈,为所有这个词行业的畴昔发展设备出一派全新且精深的六合,有望引颈具身机器东说念主迈向全新的发展阶段。
草榴最新地址从表面见地到有用落地,Psi R0解答了具身智能交易化的终极命题
长程任务智谋操作场景无处不在,从工场产线拼装,到就业业的拣货打包,到家居环境的清洁整理。
Psi R0模子的智能体展示了其巨大的场景落地能力。以电阛阓景为例,商品打包是典型的长程任务功课,需对上万件商品进行抓取,扫码,扬弃,塑料袋打结等多个操作。Psi R0八成使用双智谋手通顺地完成这一系列看成(此系列看成在客户现场不错取代一个完好工位),成为首个基于强化学习历练完成长程智谋操作任务的具身机器东说念主。
视频中,机器东说念主系统摄取到的教唆只是是“将桌面的物体打包”,而这一看似简便的任务背后,是灵初智能极具翻新性的端到端本事架构在透露作用。当教唆下达后,表层视觉言语模子(VLM)对桌上散乱摆放的商品进行分析,编排出商品的操作公法,基层操作模子拆解出单个商品的子任务,如抓取、扬弃、扫码、打包等,智能体次第实施。
抓取要道,面对过去摆放、局面互异的商品,模子必须具备高度的泛化能力,才能收效完成商品的逐一抓取。视频中展示的品客薯片,Psi R0 只是依靠 20 条真机数据,模子就收效完了了99%+的收效抓取率。

扫码要道更是进修机器东说念主的智谋操作水平,需要双手高度概述地配合彼此相对位置,以确保扫码枪与商品条码八成精确对皆,任何隐微偏差都可能导致扫码失败。此时,RL历练计策为双手双臂组成的高解放度复杂系统提供了可靠的及时闭环死心,保险扫码看成精确通顺地完成。
打包要道,需要双手配合完成对塑料袋的智谋操作。在动态打包的历程中,塑料袋的局面会随看成变化,需要及时养息操作。为了教训机器东说念主对柔性物体的操作相宜能力,Psi R0在仿真环境中模拟多种柔性物体的操作场景,同期荟萃真机数据进行微调优化。以至在被打断、插手的情况下,也能自相宜养息计策,重新进行打包看成。

灵初智能Psi R0模子是具身智能递归性成长的第一步。具身智能将纳降勤俭单到复杂、从保护到协同的渐进式演进。在早期,小脑是与真实宇宙交互的物理基础,其联想需荟萃限制常识,知足环境中的拘谨条目,同期具备容错性,维持大脑学习与优化。Psi R0模子透露RL算法探索的上风,维持小脑的快速迭代,生成维持长程智谋操作的智能体。通过智谋操作动掸数据飞轮,完了从小脑Action到大脑Cognition的闭环回馈,出手大脑融会能力优化,模子继续迭代,变成小脑协同+大脑优化的具身智能“神经回路”,使端到端模子完成勤俭单到复杂、从保护到协同的渐进式演进。
本文起头:财经报说念网
 西野翔作品番号
西野翔作品番号





